Reconocimiento óptico de caracteres (OCR)
Estos modelos utilizan versiones ligeras optimizadas para la web, lo que limita su precisión. Están diseñados exclusivamente para fines experimentales, permitiéndote interactuar con el pipeline básico y analizar los datos de salida.
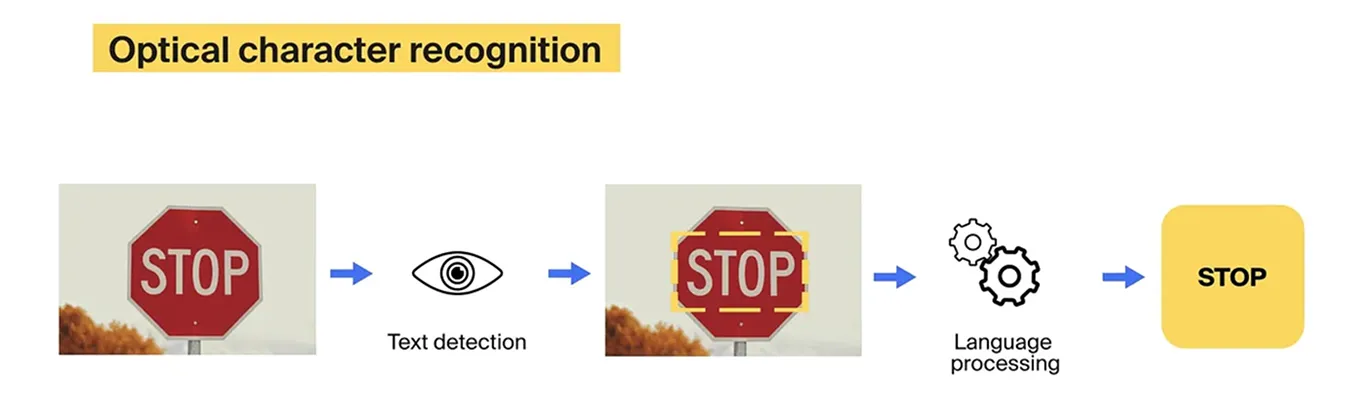
¿Qué es el OCR (Reconocimiento Óptico de Caracteres)?
Es una tecnología fundamental en la digitalización de documentos donde un modelo de IA analiza una imagen y extrae el texto contenido en ella, transformándolo en un formato editable por máquina.
Para lograrlo, el motor analiza los patrones de píxeles oscuros y claros para identificar líneas, letras y palabras. Tesseract, en particular, utiliza redes neuronales recurrentes (LSTM) para predecir la secuencia de caracteres basándose en el contexto y diccionarios de idiomas pre-entrenados.
Motores disponibles para realizar pruebas
Una de las características clave de Tesseract es su capacidad para menajar más de 100 idiomas, lo que lo convierte en una opción fiable para proyectos multilingües. Las continuas mejoras han aumentado su fiabilidad en la lectura de texto impreso, especialmente en documentos estructurados como formularios e informes.
Tesseract se utiliza comúnmente en proyectos que implican el escaneo de facturas, el archivo de documentación o la extracción de texto de documentos con diseños estándar. Funciona mejor cuando la calidad del documento es buena y el diseño no varía significativamente.
