Avances entre el siglo XX Y XXI
Durante los últimos sesenta años, la Visión por Computadora ha evolucionado como una disciplina clave en la inteligencia artificial, con el objetivo de dotar a las máquinas de la capacidad para interpretar imágenes y escenas del mundo tal como lo hace el ser humano. Este campo combina conocimientos de neurociencia, matemáticas, ingeniería y computación para imitar el proceso visual humano mediante algoritmos y modelos computacionales.
A continuación, se presenta un recorrido cronológico con algunos de los hitos más importantes que marcaron el desarrollo de esta área, desde sus fundamentos biológicos hasta los avances actuales con redes neuronales profundas.
1959 - Experimentos en gatos
Uno de los primeros pasos hacia la comprensión de la visión fue dado por los neurofisiólogos David H. Hubel y Torsten N. Wiesel, quienes estudiaron cómo el cerebro procesa la información visual. En su investigación Receptive Fields of Single Neurones in the Cat's Striate Cortex, realizaron experimentos registrando la actividad de neuronas individuales en la corteza visual de gatos.
Los estudios mostraron que ciertas neuronas se activaban únicamente ante estímulos visuales específicos, como líneas u orientaciones particulares. Además, observaron que algunas neuronas respondían solo a un ojo (ipsilateral o contralateral), mientras que otras eran activadas por ambos.
1963 - Representación tridimensional a partir de imágenes 2D
Lawrence G. Roberts, considerado uno de los pioneros de la visión por computadora, presentó su tesis doctoral Machine Perception of Three-dimensional Solids, donde abordó el problema de reconstruir objetos tridimensionales a partir de imágenes bidimensionales.
En el capítulo 3, menciona que la percepción de la profundidad en una imagen monocular se basa completamente en las suposiciones del observador. Algunas de estas suposiciones se refieren a la naturaleza del mundo real y otras se basan en la familiaridad del observador con los objetos.
La primera suposición es que la imagen es una vista del mundo real registrada por una cámara o un dispositivo similar y, por lo tanto, que la imagen es una transformación de perspectiva de un campo tridimensional. Esta transformación es una proyección de cada punto del espacio de visión hacia un punto focal, sobre un plano.
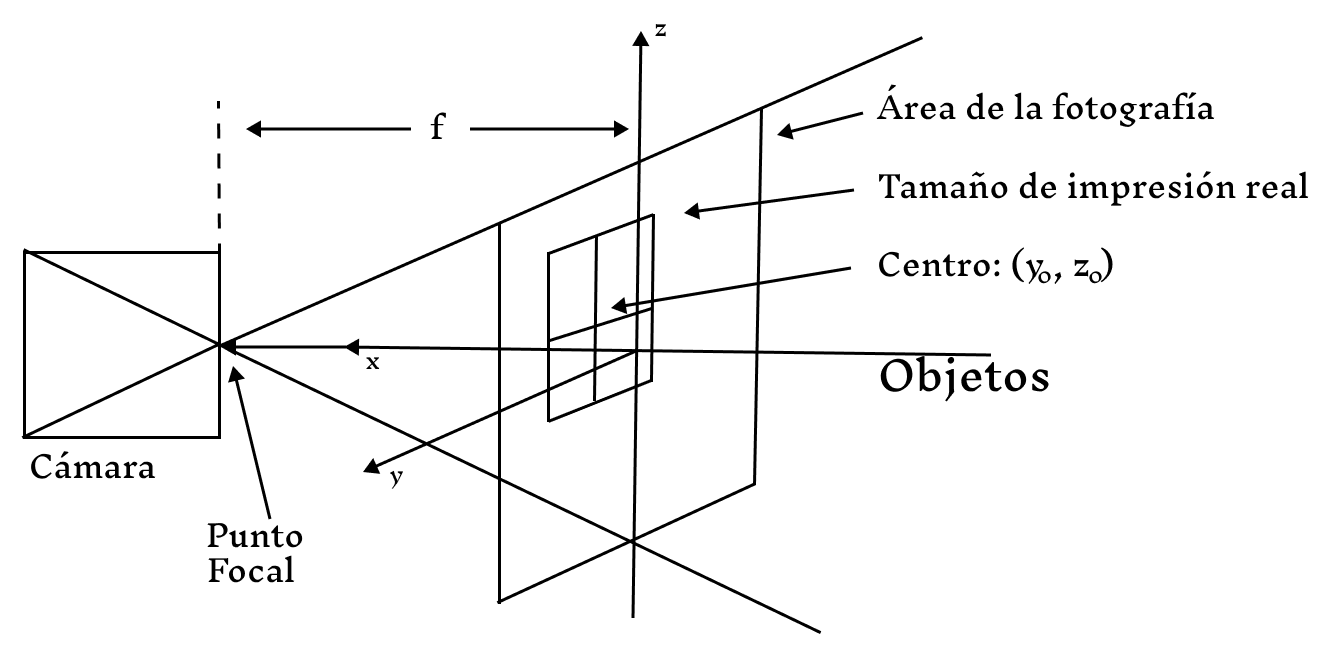
Figura 1: Proyección en perspectiva de una cámara en un espacio tridimensional.
1974 - Reconocimiento Óptico de Caracteres
Ray Kurzweil fundo la compañía Kurzweil Computer Products con el objetivo de desarrollar un sistema OCR (Optical Character Recognition) que pudiera leer texto impreso en cualquier tipo de fuente. Este sistema, denominado omni-font OCR, representó un gran avance proque no dependía de una fuente específica para reconocer los caracteres.
Kurzweil aplicó esta tecnología para crear una máquina lectora que ayudara a personas ciegas, convirtiendo texto impreso en voz. Esta fue una de las primeras aplicaciones prácticas de la visión por computadora.

Figura 2: Ray Kurzweil con su máquina lectora para personas ciegas.
1982 - Modelo jerárquico de visión y detección de bordes
David Marr, investigador del MIT, propuso un influyente modelo teórico sobre cómo el sistema visual humano procesa imágenes. En su libro Vision, Marr planteó que la visión se desarrolla en etapas jerárquicas, desde la detección de bordes hasta la representación tridimensional del entorno.
Marr menciona que el desenfoque de las imágenes es el primer paso para detectar cambios de intensidad en ellas. El problema se simplifica mucho en una imagen que ha sido desenfocada con un filtro gaussiano, porque, en efecto, existe un límite superior a la velocidad a la que pueden producirse los cambios. La primera parte del proceso de detección de bordes puede considerarse como la descomposición de la imagen original en un conjunto de copias, cada una de ellas filtrada con un gaussiano de diferente tamaño.

Figura 3: Desenfoque de imagen para detectar distintas intesidades.
1982 - Neocognitron
Kunihiko Fukushima desarrolló el Neocognitron, una red neuronal multicapa inspirada en el sistema visual humano. Esta arquitectura fue capaz de reconocer patrones visuales como caracteres escritos a mano, y es considerada precursora directa de las redes neuronares convolucionales (CNN).
A esta red se le ha dado el sobrenombre de Neocognitron ya que es una extensión del cognitron, que también es un modelo de red neuronal multicapa auto-organizada propuesto anteriormente por Fukushima.
El Neocognitron propuesto tiene la capacidad de reconocer patrones de estímulos sin verse afectado por cambios en la posición ni por pequeñas distorsiones en la forma de los patrones de estímulos. También tiene una función de autoorganización, que progresa mediante el aprendizaje sin maestro (learning without a teacher). Si se le presenta repetidamente un conjunto de patrones de estímulos, adquiere gradualmente la capacidad de reconocer estos patrones. No es necesario dar ninguna instrucción sobre las categorías a las que deben pertenecer los patrones de estímulos.
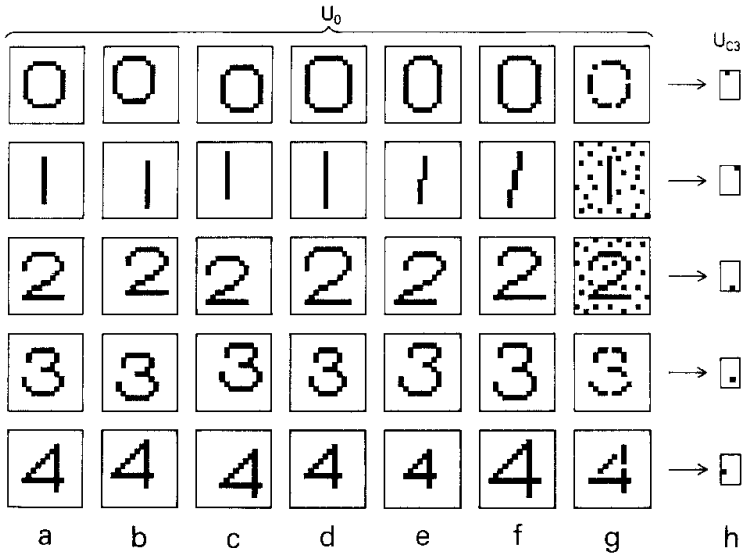
Figura 4: Ejemplo neocognitron con números.
2001 - Reconocimiento facial en tiempo real
Paul Viola y Michael Jones desarrollaron un algoritmo eficiente para detectar rostros en imágenes, descrito en su artículo Rapid Object Detection using Boosted Cascade of Simple Features. El método utilizaba una casca de clasificacodres entrenados mediante boosting, junto con un conjunto de características simples llamadas Haar-like features. Este enfoque permite detectar rostros de manera rápida y confiable, incluso en dispositivos con capacidad limitada de procesamiento.
Para entrenar el detector, se utilizó un conjunto de imágenes de entrenamiento con rostros y sin rostros. El conjunto de entrenamiento con rostros constaba de 4.916 rostros etiquetados a mano, escalados y alineados a una resolución base de 24 por 24 píxeles. Los rostros se extrajeron de imágenes descargadas durante un rastreo aleatorio de la World Wide Web. En la figura 5 se muestran algunos ejemplos típicos de rostros.

Figura 5: Ejemplo de imágenes frontales de rostros en posición vertical utilizadas para el entrenamiento.
2010 - ImageNet
ImageNet es una base de datos de imágenes etiquetadas que se convirtió en el estándar para entrenar y evaluar modelos de visión por computadora. En 2010, a través del concurso ILSVRC2010, Olga Russakovsky, Li Fei-Fei et al. ganaron el concurso y el conjunto de datos contenía millones de imágenes etiquetadas con mil clases de objetos. Esto proporciono una base para las CNN y los modelos de Deep Learning que se utilizan en la actualidad.
El concurso de ImageNet Large Scale Visual Recognition Challenge (ILSVRC) evalúa algoritmos para la detección de objetos y la clasificación de imágenes a gran escala. Una de las principales motivaciones es permitir a los investigadores comparar los avances en la detección de una mayor variedad de objetos, aprovechando el costoso esfuerzo del etiquetado. Otra motivación es medir los avances de la visión artificial en la indexación de imágenes a gran escala para su recuperación y anotación.
En 2015, Olga Russakovsky, Li Fei-Fei et al. publicaron un artículo titulado ImageNet Large Visual Recognition Challenge especificando con más detalles los resultados obtenidos.
Como se puede ver en la Figura 6, el conjunto de datos contiene muchas más clases detalladas en comparación con el benchmark estándar PASCAL VOC. Por ejemplo, en lugar de la categoría perro de PASCAL, hay 120 razas diferentes de perros en las tareas de clasificación y localización de objetos únicos.

Figura 6: Ejemplo de conjunto de datos.
2012 - AlexNet
En 2012, Alex Krizhevsky, Ilya Sutskever y Geoffrey Hinton presentaron AlexNet, una red neuronal convolucional que ganó el ILSVRC2012 al reducir drásticamente el error en clasificación de imágenes. En el artículo ImageNet Classification with Deep Convolutional Neural Networks mencionan que su arquitectura incluía múltiples capas convolucionales, funciones de activación ReLU y técnicas como dropout y uso de GPU's para acelerar el entrenamiento.
Alex Krizhevsky et al. mencionan que el método más sencillo y habitual para reducir el sobreajuste en los datos de imágenes es ampliar artificialmente el conjunto de datos mediante transformaciones que conservan las etiquetas. Emplearon dos formas distintas de aumento de datos, ambas permiten producir imágenes transformadas a partir de las imágenes originales con muy poco cálculo, por lo que las imágenes transformadas no necesitan almacenarse en el disco. En su implementación, las imágenes transformadas se generan en código Python en la CPU mientras la GPU está entrenando con el lote anterior de imágenes.
Formas en que se aplica el aumento de datos:
- Generar traslaciones de imágenes y reflejos horizontales.
- Alterar las intensidades de los canales RGB en las imágenes de entrenamiento.

Figura 6: Ejemplo de formas en que se aplica aumentación de datos.
AlexNet marcó un punto de inflexión, demostrando que el Deep Learning era capaz de superar ampliamente a los métodos tradicionales en tareas visuales.
2016 - You Only Look Once
En 2016, Joseph Redmon et al. presentaron el modelo YOLO con el objetivo de mejorar el rendimiento en la tarea de detección de objetos. En su artículo titulado You Only Look Once: Unified, Real-Time Object Detection, los autores mencionan el uso de una única red neuronal en lugar de múltiples redes, permitiendo así que la imagen sea evaluada de forma global. Esto significa que la red procesa la imagen completa en una sola pasada para identificar simultáneamente todos los objetos presentes.
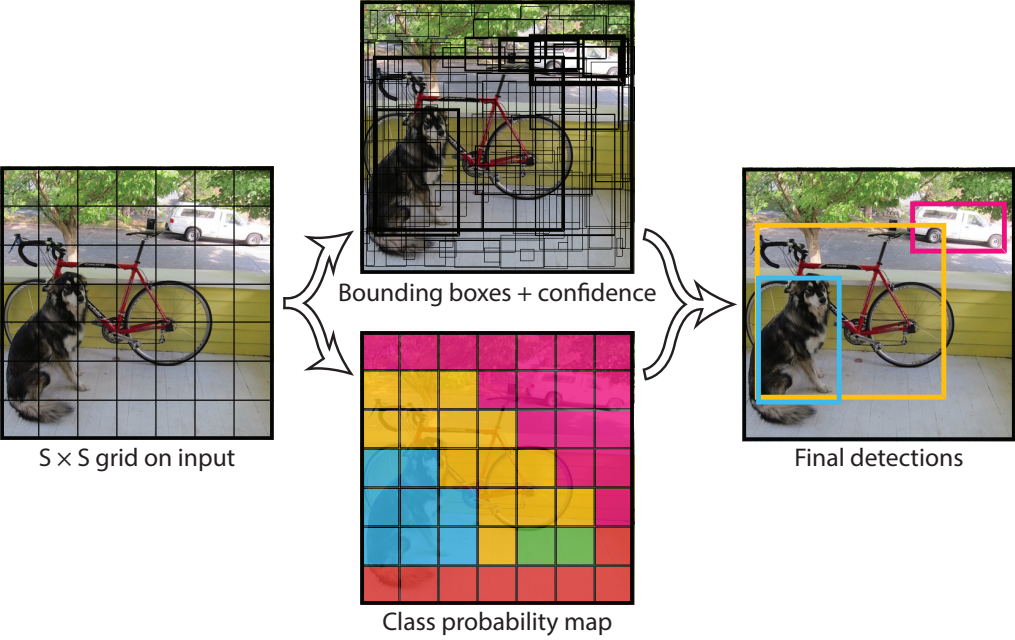
Figura 7: Proceso de detección de objetos con YOLO.